9.3 – Voice-over-IP
9.3.1 – Limitations of the Best-Effort IP Service
- Because packets can be lost and the end-to-end delay wont be the same for every packet, the receiver must take care in determining when to play back a chunk and what to do with a missing chunk.
- UDP segments generated by a VoIP applications can get lost during transmission. We could use TCP instead of UDP. However, retransmission mechanisms are often considered unacceptable for conversational real-time audio applications such as VoIP, because they increase end-to-end delay.
- Furthermore, due to TCP congestion control, packet loss may result in reduction of the TCP sender’s transmission rate to a rate that is lower than the receiver’s drain rate, possibly leading to buffer starvation.
- Overall using TCP can have a severe impact on voice intelligibility at the receiver.
- Packet loss rates between 1-20% can be tolerated, depending on how voice is encoded and transmitted, and on how the loss is concealed at the receiver.
- Forward error correction (FEC) can help conceal packet loss.
- Redundant information is transmitted along with the original information so that some of the lost original data can be recovered from the redundant information.
- Nevertheless, if one or more of the links between sender and receiver is severely congested, and packet loss exceeds 10-20% then there is really nothing that can be done to achieve acceptable audio quality.
- End-to-end delay is the accumulation of transmission, processing, and queuing delays in routers; propagation delays in links; and end-system processing delays.
- Smaller than 150 msec are not perceived by a human listener; delays between 150-400 msec can be acceptable put are not ideal; and delays exceeding 400 msec can seriously hinder the interactivity in voice conversations.
- Applications will typically disregard packets that are delayed more than a certain threshold.
- Jitter, the time from when a packet is generated at the source until it is received at the receiver can fluctuate from packet to packet.
- Example: Consider two consecutive packets in our VoIP application. The sender sends the second packet 20 msecs after sending the first one.
- But at the receiver, the spacing between these packets can become greater than 20 msecs.
- To see this, suppose the first packet arrives at a nearly empty queue at a router, but just before the second packet arrives at the queue a large number of packets from other sources arrive at the same queue.
- Because the first packet experiencing a small queuing delay and the second packet suffers a large queuing delay at this router, the first and second packet become spaced by more than 20 msecs. The spacing between consecutive packets can also become less than 20 msecs.
- If the receiver ignores the presence of jitter and plays out chunks as soon as they arrive, then the resulting audio quality can easily become unintelligible at the receiver.
- Fortunately, jitter can often be removed by using sequence numbers, timestamps, and a playout delay.
- Example: Consider two consecutive packets in our VoIP application. The sender sends the second packet 20 msecs after sending the first one.
9.3.2 – Removing Jitter at the Receiver for Audio
- The following 2 mechanisms are used to provide periodic playout of voice chunks in the presence of random network jitter:
- Prepending each chunk with a timestamp.
- Delaying playout of chunks at the receiver.
- Fixed playout delay:
- The receiver attempts to play out each chunk exactly q msecs after the chunk is generated.
- If a chunk is timestamped at the sender at time t, then the receiver plays out the chunk at time t+q, assuming the chunk has arrived by that time.
- Packets that arrive after their schedule playout times are discarded and considered lost.
- The best choice for q is hard to figure out as if it is 400 then it will support a lot of delays, but having a smaller q will result in a smoother experience if the jitter isn’t too high. But if its too small then a lot of packets may lose out on their playout time.
- Two distinct initial playout delays are considered.
- The sender generates packets at regular intervals, say, every 20 msecs.
- The first packet in this talk spurt is received at time r. The arrivals of subsequent packets are not evenly spaced due to the network jitter.
- For the first playout schedule, the fixed initial playout delay is set to $$p-r$$.
- With this schedule, the fourth packet does not arrive by its schedule playout time, and the receiver considers it lost. For the second playout schedule, the fixed initial playout delay is set to $$p-r$$.
- For this schedule, all packets arrive before their scheduled playout times, and there is therefore no loss.
- The receiver attempts to play out each chunk exactly q msecs after the chunk is generated.
Adaptive playout delay:
- The natural way to deal with the trade-off of small or big delay is to estimate the network delay and the variance of the network delay, and to adjust the playout delay accordingly at the beginning of each talk spurt.
- This will cause the sender’s silent periods to be compressed and elongated; however, compression and elongation of silence by a small amount is not noticeable in speech.
A generic algorithm that the receiver can use to adaptively adjust its playout delays:
- $$t_i=$$The timestamp of the $$i^{th}$$ packet = the time the packet was generated by the sender
- $$r_i=$$The time packet i is received by receiver
- $$p_i=$$The time packet i is played at receiver.
- The end-to-end network delay of the $$i^{th}$$ packet is $$r_i-t_i$$.
$$d_i$$ denote an estimated of the average network delay upon reception of the $$i^{th}$$ packet.
- $$di=(1-u)d{i-1}+u(r_i-t_i)$$
- u is a fixed constant
- $$d_i$$is a smoothed average of the observed network delays $$r_1-t_1,...,r_i-t_i$$. The estimate places more weight on the recently observed network delays than on the observed network delays of the distant past.
- $$di=(1-u)d{i-1}+u(r_i-t_i)$$
$$v_i$$denote an estimate of the average deviation of the delay from the estimated average delay. The estimate is also constructed from the timestamps.
- $$vi=(1-u)v{i-1}+u|r_i-t_i-d_i|$$
The estimates $$d_i$$ and $$v_i$$ are calculated for every packet received, although they are used only to determine the playout point for the first packet in any talk spurt. Once having calculated these estimates, the receiver employs the following algorithm for the playout of packets.
If packet i is the first packet of a talk spurt, its playout time:
- $$p_i=t_i+d_i+Kv_i$$
- Where K is a positive constant
- $$p_i=t_i+d_i+Kv_i$$
The purpose of the $$Kv_i$$ term is to set the playout time far enough into the future so that only a small fraction of the arriving packets in the talk spurt will be lost due to late arrivals. The playout point for any subsequent packet in a talk spurt is computed as an offset from the point in time when the first packet in the talk spurt was played out
- $$q_i=p_i-t_i$$
- The length of time from when the first packet in the talk spurt is generated until it is played out.
- $$q_i=p_i-t_i$$
If packet j also belongs to this talk spurt, it is played out at time
- $$p_j=t_j+q_i$$
- The natural way to deal with the trade-off of small or big delay is to estimate the network delay and the variance of the network delay, and to adjust the playout delay accordingly at the beginning of each talk spurt.
9.3.3 – Recovering from packet loss
- Schemes that attempt to preserve acceptable audio quality in the presence of packet loss is named loss recovery schemes.
- A packet is lost either if it never arrives at the receiver or it it arrives after its scheduled playout time.
- Retransmitting a packet that has missed its playout deadline server absolutely no purpose. And retransmitting a packet that overflowed a router queue cannot normally be accomplished quickly enough. Thus VoIP applications use some type of loss anticipation scheme.
- Two types of loss anticipation schemes:
- Forward error correction (FEC)
- Interleaving
- Forward error correction (FEC)
- The basic idea is to add redundant information to the original packet stream.
- For the cost of marginally increasing the transmission rate, the redundant information can be used to reconstruct approximations or exact versions of some of the lost packets.
- The first mechanism sends a redundant encoded chunk after every n chunks. The redundant chunk is obtained by exclusive OR-ing the n original chunks.
- If any one packet of the group of n+1 packets is lost, the receiver can fully reconstruct the lost packet.
- If two or more packets ina group are lost, the receiver cannot reconstruct the packets.
- By keeping n+1, the group size, small, a large fraction of the lost packets can be recovered when loss is not excessive. However, the smaller the group size, the greater the relative increase of the transmission rate.
- The transmission rate increases by a factor of $$\frac{1}{n}$$ for every n.
- This simple scheme also increases the playout delay, as the receiver must wait to receive the entire group of packets before it can begin playout.
- The second mechanism is to send a lower-resolution audio stream as the redundant information.
- The sender might create a nominal audio stream and a corresponding low-resolution, low-bit rate audio stream.
- The low-bit rate stream is referred to as the redundant stream.
- The sender constructs the $$n^{th}$$ packet by taking the $$n^{th}$$ chunk from the nominal stream and appending to it the (n-1)st chunk from the redundant stream.
- Whenever there is nonconsecutive packet loss, the receiver can conceal the loss by playing out the low-bit rate encoded block that arrives with the subsequent packet.
- The receiver only has to receive 2 packets before playback, so that the increased playout delay is small. Furthermore, if the low-bit rate encoding is much less than the nominal encoding, then the marginal increase in the transmission ate will be small.
- In order to cope with consecutive loss we can instead of appending just the (n-1)st low-bit rate chunk to the $$n^{th}$$ nominal chunk, the sender can append the (n-1)st and (n-2)nd low-bit rate chunk, or append the (n-1)st and (n-3)rd low-bit rate chunk and so on.
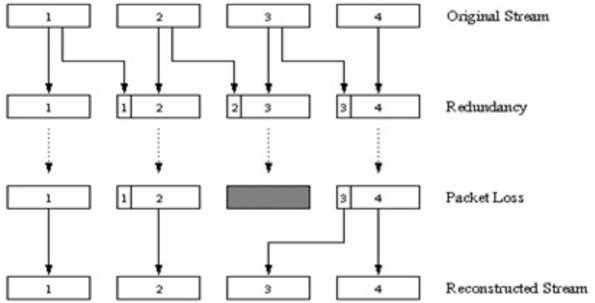
- The sender might create a nominal audio stream and a corresponding low-resolution, low-bit rate audio stream.
- Interleaving
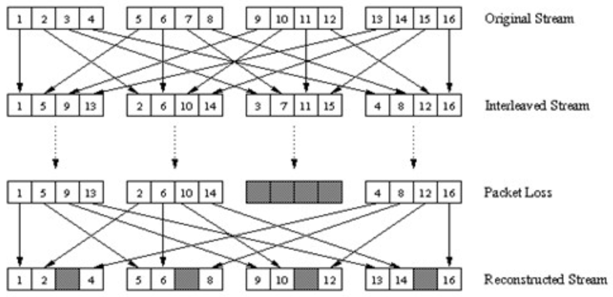
- A VoIP application can send interleaved audio. The sender resequences units of audio data before transmission, so that originally adjacent units are separated by a certain distance in the transmitted stream.
- It can mitigate the effect of packet loss. If, for example units are 5 msec in length and chunks are 20 msec, then the first chunk could contain units 1, 5, 9, and 13; the second chunk could contain units 2, 6, 10, 14; and so on.
- The loss of a single packet from an interleaved stream results in multiple small gaps in the reconstructed stream, as opposed to a single large gap that would occur in a noninterleaved stream.
- It has low overhead, but it can increase latency. This limits its use for conversational applications such as VoIP. A major advantage however, is that it doesn’t increase the bandwidth requirements of a stream.
- Error concealment schemes attempt to produce a replacement for a lost packet that is similar to the original.
- This is possible since audio signals, and in particular speech, exhibit large amounts of short-term self-similarity.
- These techniques work for relatively small loss rates (>15%) and for small packets (4-40msec).
- When the loss length approaches the length of a phoneme (5-100msec) these techniques break down. Since whole phonemes may be missed by the listener.
- The simplest form of receiver-based recovery is packet repetition. It replaces lost packets with copies of the packets that arrived immediately before the loss.
- It has low computational complexity and performs reasonably well.
- Interpolation uses audio before and after the loss to interpolate a suitable packet to cover the loss.
- It performs somewhat better than packet repetition but is significantly more computationally intensive.
9.3.4 – Case Study: VoIP with Skype
- Skype’s protocol is proprietary, and because of Skype’s control and media packets are encrypted, it is difficult to precisely determine how skype operates.
- For both voice and video, the skype clients have at their disposal many different codecs, which are capable of encoding the media at a wide range of rates and qualities.
- It has been measured it can be as low as 30 Kbps and up to 1 Mbps
- Typically, Skype’s audio quality is better than “POTS” (Plain old telephone service)
- Skype typically sample voice at 16000 samples/sec while POTS is 8000.
- By default Skype sends audio and video packets over UDP. However, control packets are sent over TCP, and media packets are also sent over TCP when firewalls block UDP streams.
- Skype uses FEC for loss recovery for both voice and video streams sent over UDP.
- Skype also adapts the video and audio streams it sends to current network conditions by changing the video quality and FEC overhead.
- Skype uses P2P techniques in wide variety of ways.
- Skype employs P2P techniques for user location and for NAT traversal.
- The peers in skype are organized into a hierarchical overlay network, with each peer classified as a super peer or ordinary peer.
- Skype maintains an index that maps Skype usernames to current IP addresses and port numbers.
- This index is distributed over the super peers.
- When someone needs an IP address the skype client searches the distributed index.
- It is not known of the index mappings are organized across the super peers.
- P2P techniques are also used in skype relays, which are useful for establishing calls between hosts in home networks. Many home network configurations provide access to the Internet through NATs. If both skype callers have NATs, then there is a problem as neither can accept a call initiated by the other. This is solved with the skype relays.
- Suppose that when Alice signs in, she is assigned to a non-NATed super peer and initiates a session to that super peer. This session allows Alice and her super peer to exchange control messages.
- The same happens for Bob when he signs in.
- When Alice wants to call Bob, she informs her super peer, who in turn informs Bob’s super peer, who in turn informs Bob of Alice’s incoming call.
- If Bob accepts the call, the two super peers select a third non-NATed super peer (the relay peer) whose job will be to relay data between Alice and Bob.
- Alice’s and Bob’s super peers then instruct them to initate a session with the relay.
- With $$N>2$$ participants, if each user were to send a copy of its audio stream to $$N-1$$ each other users, then a total of $$N(N-1)$$ audio streams would need to be sent into the network to support the audio conference.
- To reduce the bandwidth usage of multiple participants skype employs a technique where each user sends its audio stream to the conference initiator. The conference initiator combines the audio streams into one stream and then sends a copy of each combined stream to each of the other $$N-1$$ participants.
- VoIP systems introduce new privacy concerns as f.ex. skype allows users to sniff other user’s IP address’.